国民の共有財産であるレセプト情報・特定健診等情報データベース(NDB)の膨大なデータを1),便利かつ適切に利活用できるようにすることは社会的な使命と言えるが,世界最大級のNDBデータを簡単・高速・精緻に解析可能とするのは容易なことではない。
日立は,一般財団法人 医療経済研究・社会保険福祉協会 医療経済研究機構(医療経済研究機構)および東京大学生産技術研究所(東大生研)とのオープンイノベーションにより,NDBデータから新たなエビデンス創出を支援する次世代NDBデータ研究基盤SFINCSを開発した。
本稿では,SFINCSを将来にわたって活用され続けるシステムにするために日立が実施した三つの取り組みと,医療経済研究機構の研究プロジェクトによるNDBデータの利活用成果について述べる。






日本政府により未来社会の姿として提唱されている「Society 5.0」を受けて,ヘルスケア分野においては,画一的な治療から個人に合った治療へ,病気の治癒から未病ケア・予防へとシフトしていくことが提案されている2)。これらの提案を受けた医療サービスの質の向上や,膨らみがちな社会保障費のコントロール等を実現する鍵として注目されているのが,NDB(National Database of Health Insurance Claims and Specific Health Checkups of Japan:レセプト情報・特定健診等情報データベース)に格納された膨大なデータである。
NDBデータは,2008年に改正された「高齢者の医療の確保に関する法律」第16条に基づき保険者等から収集されたレセプト情報等のデータ※1)であり,その量は2018年3月末時点で約9年分,データ件数は150億件に達している3)。2013年度からは,公益性のある研究におけるNDBデータの使用が認められ,有識者会議による許可を受けた研究グループに第三者提供が開始されている4)。この世界最大級のNDBデータを,便利かつ適切に利活用するための研究基盤を整えることは社会的な使命であると言える。
そこで医療経済研究機構は,2016年度に国立研究開発法人 日本医療研究開発機構(AMED)から受託した「エビデンスの飛躍的創出を可能とする超高速・超学際次世代NDBデータ研究基盤構築に関する研究」(以下,「本研究」と記す。)において,東大生研および日立とのオープンイノベーションによる次世代NDBデータ研究基盤の確立に向けて研究を開始した5)。
医療経済研究機構,東大生研,そして日立の協創により,それぞれが持つ優れた知見や技術6),7),そして三者に共通する「社会に貢献したい」という強い思いが,本研究の目的である次世代NDBデータ研究基盤の構築を実現し,さらに当該基盤の維持・発展を可能とする研究・開発体制の整備等,大きな成果をもたらした8)。この「次世代NDBデータ研究基盤」が,本稿で紹介する超高速・超学際レセプト情報等ビッグデータ解析プラットフォームシステム(Super-Fast super-INterdisciplinary japanese medical insurance Claim bigdata analytics platform System:SFINCS)である。
SFINCSは2012年より東大生研が開発・運用している「高速レセプト解析システム」をベースにしている9),10)。利用者は,SFINCS Appを介してデータベースにアクセスし解析を行う(図1参照)。SFINCSは,2017年に稼働を開始し,現在,2009年〜2014年の6年分のNDBデータと4年分の自治体データ(健診・医療・介護)を蓄積している。
SFINCSの開発においてこだわったのは,「将来にわたって活用され続けるシステム」にすることである。現在見えている課題だけでなく,今後発生しうる課題への対応を強く意識したシステムの開発は,日立にとって大きな挑戦であった。本章では,SFINCSの開発における日立の取り組みについて述べる。
図1|SFINCS:2,000億レコード超のデータベースと20個超の解析ツールで構成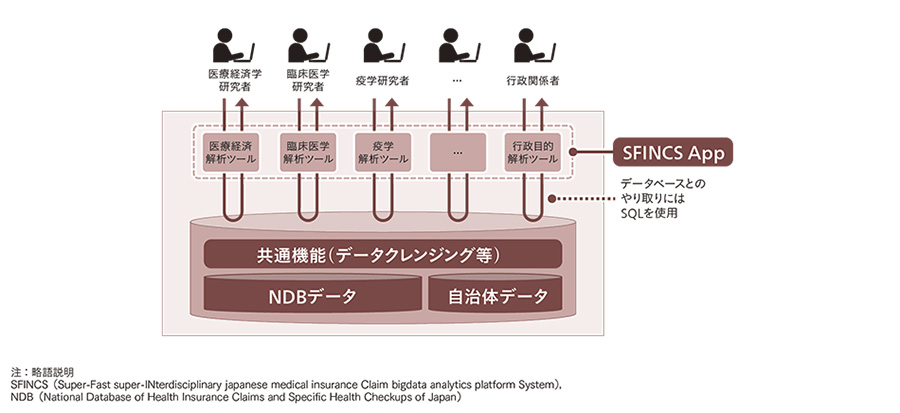 さまざまな利用者が,膨大なNDBデータを簡単・高速・精緻に解析できる。
さまざまな利用者が,膨大なNDBデータを簡単・高速・精緻に解析できる。
SFINCSの開発において,日立が最初に取り組んだのは「システムを容易に拡張できる」ように設計することである。
現在,SFINCSに格納されている6年分のNDBデータの規模は,約2,000億レコードにのぼる11)。このような膨大なデータに対する解析処理を超高速に行うために,従来は特殊なハードウェアを用いたり,特殊なプログラミングを行ったりしていた。例えば,スーパーコンピュータ並みの高価なハードウェアを利用したり,匠の域である専門性の高いプログラムを作成したりすることによって,処理時間の短縮を図っていた。しかし,このやり方では,システムの増強や機能追加のために,特殊かつ高度な開発スキルを持つ人材を潤沢に確保し続けなければならない。特殊な技術や特殊な人材の使用は,システムの容易な拡張を阻害する要因となる上,コスト高にもつながる。このことが,従来のシステム開発における課題であった(図2左側参照)。
この課題に対して,日立は,特殊なハードウェアやプログラミングを必要とせず,徹底的にオープンな技術に基づいたシステム開発を行うこととした(図2右側参照)。例えば,解析ツールであるSFINCS Appとデータベースとのやり取りには,標準かつオープンな規格であるSQLを採用した。SQLであればSFINCS Appの機能追加や変更も容易である。また,IT技術者の約6割はSQLを利用した開発を行っているという調査結果もあり12),今後も人材を安定的に確保できる可能性が高い。IT業界における人材不足が社会的な問題になっている昨今,人材確保のリスクを可能な限り低くしておくことは,成長し続けるシステムにおいて必要不可欠である。このように,技術面だけでなく人材面からも検討を行うことで,「将来にわたって容易に拡張できるシステム」を実現できた。
システムの容易な拡張を可能としたことで,利用者の要望により多種多様なSFINCS Appがリリースされ,その数は2019年6月時点で20種類を超えるまでになった。SFINCS Appを使用すれば,NDBの独特な構造の知識やデータ抽出用のプログラムを開発するスキルがなくても,画面操作により容易にデータ解析が行える。今後も利用者の要望に合わせて,SFINCS Appを拡充していく予定である。
図2|徹底的にオープンな技術:人材を安定的に確保できシステムの容易な拡張が可能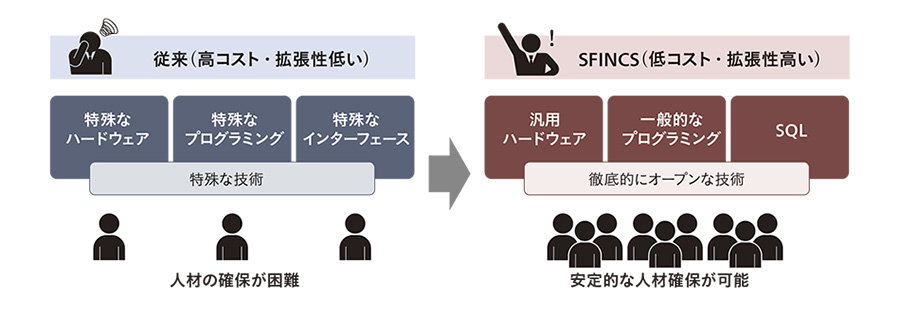 SQL等のオープンな技術を使用した開発により,「将来にわたって容易に拡張できるシステム」を実現している。
SQL等のオープンな技術を使用した開発により,「将来にわたって容易に拡張できるシステム」を実現している。
次に日立が取り組んだのは,「高速な解析処理と機動的なサービス提供を両立させる」ことである。マイクロソフト創業者のビル・ゲイツ氏も,著書の中で「スピードは企業の命(the company’s survival depends on everyone moving as fast as possible)」と述べているとおり13),「速さ」の持つ価値の普遍性は高い。NDBの利用者にとっても,自身が着想した解析手法を迅速に実践できることは重要である。解析作業が長時間に及ぶことは,利用者にとって「解析不可能である」ことと同義であり,解析手法の着想から解析結果の入手までの時間は可能な限り短くしなければならない。
解析処理の速度は解析対象のデータ量に左右されるが,NDBは今後も年に約350億レコードずつデータが増加していく11)。増加し続けるデータに対して高速な解析処理を実現するために,従来は必要なデータを抽出して目的別のデータベース(データマート)を作成することが定石であった。しかし,このやり方では,利用者から新たな要望が寄せられるたびにデータマートの作成が必要であり,プログラム開発とデータベース設計の双方に対応する時間と手間がかかる。しかも,作成したデータマートを格納するためのストレージ装置を別途準備する必要があり,その導入・運用に係る費用が発生してしまう。つまり,データマートこそが,機動的なサービス提供を行う上で課題であった(図3左側参照)。
この課題に対して,日立は,データマートに頼らなくても高速な解析処理が可能な基盤を作ることで対応した(図3右側参照)。まずは,東大生研とのオープンイノベーションにより開発した超高速データベースエンジンHitachi Advanced Data Binder※2)をSFINCSのデータ処理基盤に採用し14),処理時間の大幅な短縮を図った。さらに,増加し続けるデータとSFINCS Appの拡張の双方に対応可能とするため,データベースのデータ構造(データの持ち方)を検討した。データベースの専門家たちが,解析処理に係るさまざまな情報を基に試行錯誤を繰り返し,増加し続けるデータとSFINCS Appの拡張の双方に対応可能なデータ構造を作り上げた。このように,定石にとらわれずに課題解決の道を探ることで,「高速な解析処理と機動的なサービス提供が可能なシステム」を実現できた。
高速なデータ解析を可能としたことで,従来は日単位または時間単位での時間を要していた解析処理が,分単位または秒単位にまで短縮された。さらに,データマートに頼らずに全データを高速に解析できるため,悉皆(しっかい)調査や深掘も容易に行えるようになった。また,機動的なサービス提供を可能としたことで,例えば,SFINCSの開発中に利用者から寄せられた要望を,スピーディに形にすることができた。
図3|データマートに頼らない基盤:高速なデータ解析と機動的なサービス提供が可能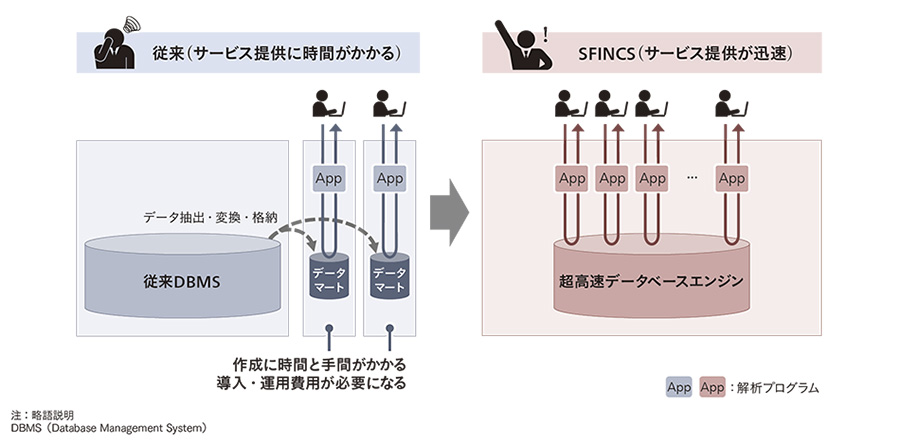 データマートに頼らない「高速な解析処理と機動的なサービス提供が可能なシステム」を実現している。
データマートに頼らない「高速な解析処理と機動的なサービス提供が可能なシステム」を実現している。
さらに日立は「利用者が解析作業に注力できるようにする」ことにも取り組んだ。ビッグデータの解析においては,実際にデータ解析を行っている時間よりも解析前に行う事前準備,例えばデータの収集・整理や,解析に必要な環境構築等に多くの時間を割いていると言われている。特に,データを解析しやすくするためのさまざまな加工処理(データクレンジング)については,全作業時間の50%〜80%を占めているという調査結果も出ている15)。
NDBデータの解析においても,医療機関ごとに月単位でまとめられているレセプト情報を個人単位で集約したり,医科レセプトと調剤レセプトのように種類の異なるレセプト情報を突合したりするなど,データの関係性を明確にして解析しやすくするための加工処理は欠かせないものとなっている。こうした加工処理を各々の利用者が個別に行う必要があり,解析作業に着手するまでに多大な時間がかかっていたことが,従来のNDBデータ解析における課題であった(図4左側参照)。
この課題に対して,日立は,上記のような加工処理をSFINCS AppではなくSFINCSの共通機能として実装することで利用者による処理を不要とし,利用者が処理を意識することなくデータ解析を行えるようにした(図4右側参照)。
さらに日立は,加工処理の仕組みに柔軟性を持たせるよう工夫した。例えば,上記の加工処理のうち,個人単位でのデータ集約は一般的に「名寄せ」と呼ばれており,さまざまな仕組みが研究されている16),17),18)。SFINCSへの実装にあたり,どのような名寄せの仕組みがあるか調査を進めたところ,名寄せ結果にどこまで厳密さを求めるか等によって,適切な仕組みが異なってくることがわかった。このため,解析目的に合わせて別の名寄せの仕組みを追加し,利用者が名寄せの仕組みを使い分けられるような実装としている。このように,特定の仕組みにとらわれない実装とすることで,「利用者が解析作業に注力できるシステム」を実現できた。
図4|データクレンジング機能の実装:利用者はすぐに解析作業に着手可能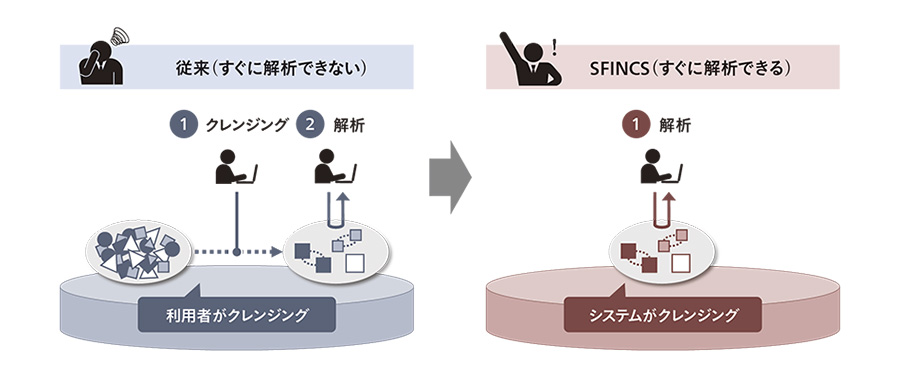 データクレンジング機能の実装により,「利用者が解析作業に注力できるシステム」を実現している。
データクレンジング機能の実装により,「利用者が解析作業に注力できるシステム」を実現している。
SFINCSを核とした,医療経済研究機構の研究プロジェクトには,2019年6月時点で15大学,6学会,60名を超える有識者が参加している。このようにNDBデータ解析者の裾野が広がり,NDBデータを使用した研究が盛んになったことは,SFINCS開発の大きな成果と言える。本章では,研究プロジェクトによるNDBデータの利活用成果の一例を紹介する。
近年の研究において,高血圧や糖尿病等の生活習慣病は,寿命だけでなく医療費にも大きな影響を与えることが判明しており,予防に向けて厚生労働省や健康保険組合,地方自治体等でさまざまな取り組みが行われている。
医療経済研究機構の満武巨裕上席研究員が医療の質の評価等を目的に実施したNDBデータの解析調査において,生活習慣病(高血圧,糖尿病,高脂血症,腎不全)の患者数や診療実態(投薬や処置)の解析結果が(図5参照),厚生労働省が実施している「国民健康・栄養調査」および「患者調査」を基にした推計患者数と同様の傾向を示した8)。つまり,調査員を派遣して個別に調査した結果と同等の結果をNDBデータの解析調査により得られたということであり,悉皆データの高速解析による代替調査の可能性を示している。
また,本解析調査においては,全体で約1,000万人いる糖尿病患者のうち,診療ガイドラインに準じた投薬や処置を受けている患者は約350万人という実態を示し,糖尿病学会に診療ガイドラインに資する知見を還元できたと言える19)。
図5|NDBを活用した日本の糖尿病患者数と診療実態(病名・投薬・処置の組み合わせ)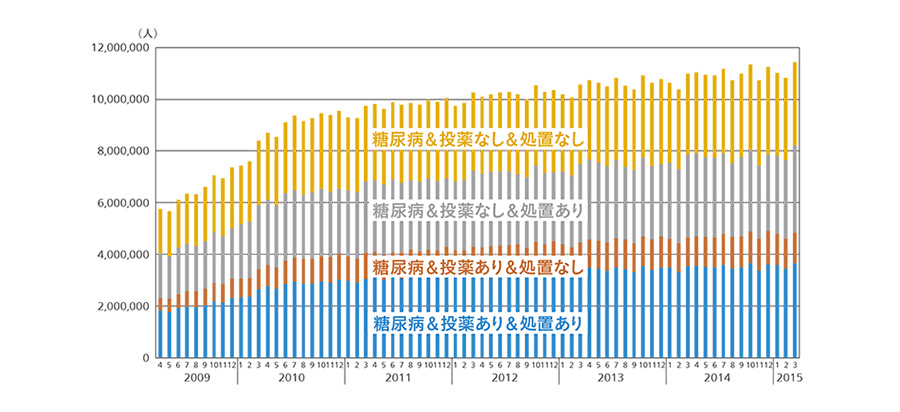 NDBデータの解析調査により,糖尿病患者に対する投薬や処置の実態を数値で把握することが可能となる。
NDBデータの解析調査により,糖尿病患者に対する投薬や処置の実態を数値で把握することが可能となる。
糖尿病にはいくつか種類があるが,その中でも患者の社会的・経済的負担が大きいのが1型糖尿病である。1型糖尿病とは,膵臓(すいぞう)のβ細胞が破壊されたことにより体内のインスリンが欠乏する疾患であり,患者は生命維持のため生涯にわたって毎日インスリン注射を行わなければならない。これには相応の費用がかかるため,医療費助成対象となるよう指定難病への認定が求められていたが,検討の俎上(そじょう)に載せるには「希少な疾患であること(国内の患者数がおおむね人口の0.1%に達しないこと)」と「客観的な診断基準があること」という二つの基準をクリアする必要があった20)。
1型糖尿病の患者数についてはこれまで把握されていなかったが,九州大学の中島直樹教授の研究グループが実施したNDBデータの解析調査において,2014年における1型糖尿病の患者数は約11.7万人と推計された21)。NDBデータの解析調査により,希少な疾患であることの裏付けとなる数値が得られ,1型糖尿病の指定難病への認定に必要な資料の一つとなった。
このように,医療経済研究機構の研究プロジェクトにより,今までにないNDBデータの利活用成果が次々と生み出されているのである。
現在,政府を中心として,NDBデータを他のさまざまなビッグデータと連携させて解析することへの機運が高まっている。その対象データの一つが介護保険のデータである。NDBデータの「誰にどのような医療行為等を実施したか」という情報と,介護保険のデータの「医療行為等の結果その人はどうなったか」という情報を連携させることで,医療行為等と認知症の進行度合いの関係性,医療費と介護費の傾向や総費用等が解析できるようになる22)。このため,研究者だけでなく,医療保険や介護保険の保険者である国や地方自治体からも注目が集まっている。
このようなNDBデータと介護保険のデータの連携という先進的な試みについて,SFINCSは先行して取り組んでいる。例えば,三重県においては,医療経済研究機構と東大生研の協力を得て,健診・医療・介護データの横断的な解析調査を基に,医療・介護の需要供給実態の可視化,特定健診受診率の向上と効率化分析,医療・介護支出の予測手法の確立等を進めている23)。地域の実情に即した医療・介護政策や効果的な財政支出策を検討していく上で,自らが保有するデータを徹底的に活用していく姿勢は,これから人口減少が進む時代において欠かせないものとなっていくだろう。
また,さらなる試みとして,SFINCSのクラウドネイティブ化とこれに対応する高速な匿名加工処理機能の実装に取り組んでいる。どちらも,革新的研究開発推進プログラム(ImPACT)の研究課題「社会リスクを低減する超ビッグデータプラットフォーム」の超ビッグデータ処理エンジン・プロジェクトにおいて24),東大生研と日立のオープンイノベーションにより開発に成功した技術であり,将来,パブリッククラウド環境におけるデータ解析を実現する上では欠かせないものである25),26),27),28)。このように,SFINCSはさまざまなビッグデータから新たなエビデンスの創出を支援する強力なプラットフォームとして今後も進化を続け,国民の健康と幸福に貢献していく。
日立は,ヘルスケア分野における豊富なシステム構築実績を強みに,健康・医療・介護分野におけるIoT(Internet of Things)施策の推進を支援している。今回,医療経済研究機構,東大生研とのオープンイノベーションにより開発したSFINCSは,ヘルスケア分野にとどまらず,ビッグデータ時代のシステムはどうあるべきかを考える上でよい参考事例になると自負している。
これからも,日立はさまざまな分野においてオープンイノベーションの取り組みを推進し,一人ひとりが生き生きと快適に暮らせる持続可能な社会の実現に向けて努力していく。
本稿で述べたSFINCSは,国立研究開発法人 日本医療研究開発機構(AMED)による臨床研究等ICT基盤構築研究事業「エビデンスの飛躍的創出を可能とする超高速・超学際次世代NDBデータ研究基盤構築に関する研究」の助成に基づき,医療経済研究機構および東京大学生産技術研究所との協創を通じて開発したシステムである。特に,医療経済研究機構の満武巨裕上席研究員および東京大学生産技術研究所の喜連川優教授と合田和生准教授をはじめとする関係各位より多くのご指導をいただいた。ここに深く感謝の意を表する。
