
デジタルトランスフォーメーションを加速するITインフラストラクチャ
執筆者
関 辰一郎Seki Shinichiro
- 日立製作所 ITプロダクツ統括本部 プロダクツサービス&ソリューション本部 クラウド&プロダクツサービス部 所属
早坂 光雄Hayasaka Mitsuo
- 日立製作所 研究開発グループ デジタルテクノロジーイノベーションセンタ データストレージ研究部 所属
志賀 賢太Shiga Kenta
- 日立製作所 ITプロダクツ統括本部 基盤ソフトウェア開発本部 所属
執筆者の詳細を見る
関 辰一郎Seki Shinichiro

- 日立製作所 ITプロダクツ統括本部 プロダクツサービス&ソリューション本部 クラウド&プロダクツサービス部 所属
- 現在,ITプロダクツのソリューション・サービス開発に従事
早坂 光雄Hayasaka Mitsuo

- 日立製作所 研究開発グループ デジタルテクノロジーイノベーションセンタ データストレージ研究部 所属
- 現在,分散スケールアウトストレージおよびデータ管理技術の研究・開発に従事
- 博士(工学)
- 情報処理学会会員
志賀 賢太Shiga Kenta

- 日立製作所 ITプロダクツ統括本部 基盤ソフトウェア開発本部 所属
- 現在,ストレージ製品の制御ソフトウェアの開発および評価に従事
- 情報処理学会会員
ハイライト
昨今,企業がデジタルトランスフォーメーションを進めるうえで,事業環境の変化に合わせて業務アプリケーションを迅速に作り変えることが求められている。このような業務アプリケーションの実行基盤として,コンテナ技術が注目されている。
本稿では,コンテナへ迅速に永続ボリュームを提供するスケーラブルなデータストアを紹介する。加えて,ITインフラストラクチャのSoftware-defined化の潮流を踏まえ,上記のデータストアを進化させた日立のデジタルインフラ向け次世代データ基盤の開発構想を紹介する。データ基盤は,業務アプリケーションを最適に稼働させ,かつそれらのデータを安全に格納することを特長としており,グローバル市場におけるLumada事業拡大を支えるものである。
1. はじめに
昨今のITには,デジタル技術やデジタル化された情報を活用することで,企業がビジネスや業務を変革し,これまで実現できなかった新しい価値を生み出すことが求められている。これらは,自社のビジネスにどのようなイノベーションを起こせるか,試行錯誤しながら見極めようとするため,短期間に低コストでプロトタイプを作ることが求められる。さらに,これらの分析には企業の競争力の源泉となる情報を扱うケースが多く,本稼働のシステムではデータを社外に出すことに抵抗を感じる企業も多い。そのため,こうしたビジネスイノベーションを実現するには,短期間に何度も試行錯誤できるアプリケーションをオンプレミスで迅速に開発できる基盤が不可欠である。
また,試行錯誤のサイクルを高速に回すためには,開発したアプリケーションをなるべく小さい単位で,かつ短いサイクルでデプロイしたいというニーズがあり,コンテナ技術※1)およびコンテナオーケストレーションツール※2)を,基盤でサポートする必要がある。
日立では,こうしたシステムを迅速に効率よく開発するため,共通機能をLumadaのプラットフォームとして提供している。Lumadaのプラットフォームでは,コンテナ技術としてOSS(Open Source Software)であるDocker※3),コンテナオーケストレーションツールとして同じくOSSのKubernetes※4)を採用しており,これらのコンテナで稼働するアプリケーション・ミドルウェアが使用するデータを高信頼かつスケーラブルに格納するデータストアが必要になった。
本稿では,前半でLumadaにおける高信頼かつスケーラブルなデータストアの実現方法を述べ,後半で日立の将来の製品開発構想を示す。
- ※1)
- ホストOS(Operating System)上に論理的な区画(コンテナ)を作り,アプリケーションを動作させるのに必要なライブラリやアプリケーションなどを一つにまとめ,あたかも個別のサーバのように使うことができるようにしたものである。コンテナはサーバ仮想化に比べオーバーヘッドが少ないため,軽量で高速に動作する特徴を持つ。
- ※2)
- コンテナをマルチホストで構成されたクラスタ構成で稼働させる際に,コンテナを統合管理(コンテナ起動/停止,稼働ホスト割り当てや生死監視など)できるツール。
- ※3)
- Dockerは,Docker, Inc.の米国およびその他の国における登録商標または商標である。
- ※4)
- Kubernetesは,The Linux Foundationの米国およびその他の国における登録商標または商標である。
2. Lumada Solution Hub向けデータストア
Lumadaでは,さまざまなデジタルトランスフォーメーション(DX:Digital Transformation)向けソリューションをカタログとしてLSH(Lumada Solution Hub)にまとめている。LSHでは,コンテナ技術を適用することで,カタログの中からソリューションを選択するだけで,IaaS(Infrastructure as a Service)上に環境を一括して構築し,ソリューションの迅速な検証を開始することが可能である。LSHのコンテナ技術ではコンテナオーケストレーションツールとしてKubernetesを採用しており,コンテナに対してKubernetesと連動して永続ボリューム,すなわちPV(Persistent Volume)を供給するストレージを提供する必要があった。
2.1 要件
LSHのコンテナ用データストアにおいて必要となる要件は,以下の四つである。
- コンテナ向けのPVを供給可能なスケーラブルなデータストアであること
- 本データストアが,複数のコンテナからRead-Write可能なPVを供給できること
- 本データストアから,オンデマンドでPVを作成・削除可能なこと
- 高信頼であること
2.2 要件への対応策
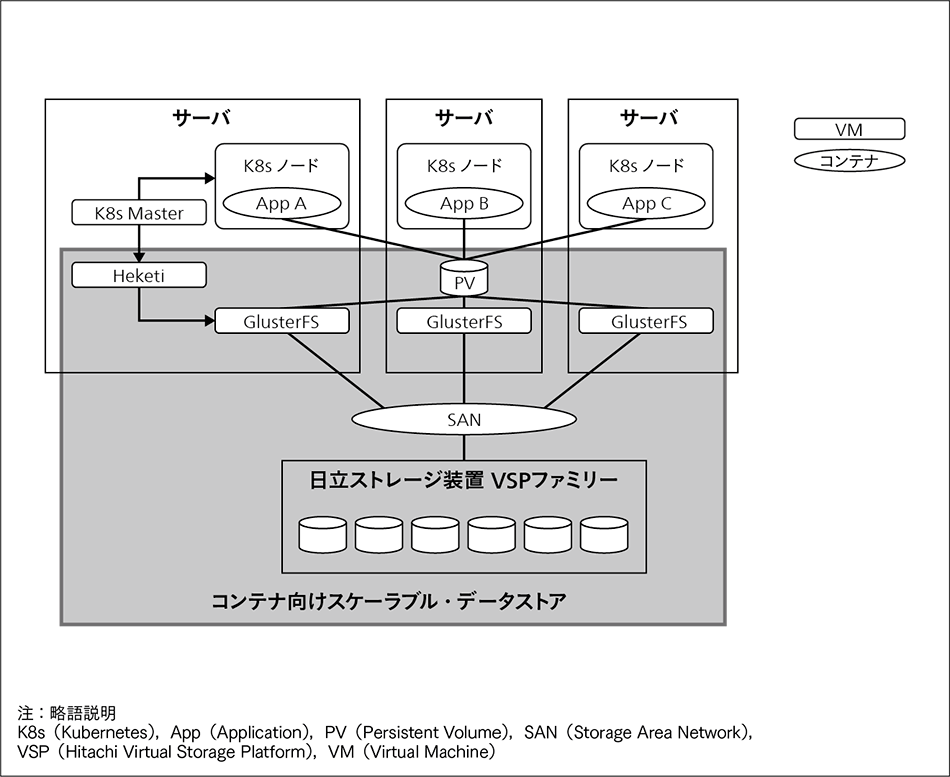
図1|コンテナ向けスケーラブル・データストア GlusterFSとHeketiを採用することで,K8s Masterと連動し,コンテナに動的にPVを提供するスケーラブル・データストアを実現した。さらに,データ自体を日立ストレージ装置VSP上に置くことで高い信頼性を確保している。
(1)および(2)へ対応するため,OSSの分散ファイルシステムであるGlusterFS※5)を採用した。GlusterFSは,Kubernetesなどとエコシステムを構築しており,動作実績も多いからである。
(3)へ対応するため,GlusterFSの管理サービスであるOSSのHeketi4)を採用した。Heketiにより,KubernetesはGlusterFSのボリュームを動的に生成,変更,削除し,コンテナに当該ボリュームをPVとして供給することができる。
(4)に対応するため,データそのものは日立ストレージ装置VSP(Hitachi Virtual Storage Platform)ファミリーへ格納し,日立の高信頼・高性能なデータ保護を適用できるようにした。
これらの対応策を取り込み,図1に示すコンテナ向けスケーラブル・データストアを開発し,2019年7月に提供を開始した。
- ※5)
- GlusterFSは,Gluster, Inc.の米国およびその他の国における登録商標である。
3. Software-definedの潮流を踏まえた製品開発構想
図2|デジタルインフラ向け次世代データ基盤 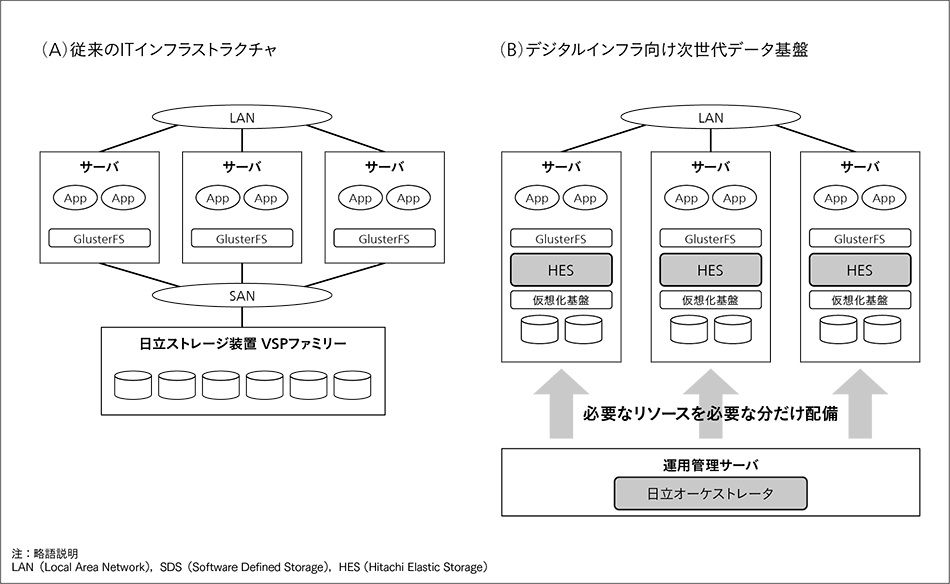 従来のITインフラストラクチャでは,リソースがハードウェアにくくりついていた。次世代データ基盤は,リソースを仮想化し,必要なリソースを必要な分だけサーバに配備することで,迅速性と柔軟性を高める。
従来のITインフラストラクチャでは,リソースがハードウェアにくくりついていた。次世代データ基盤は,リソースを仮想化し,必要なリソースを必要な分だけサーバに配備することで,迅速性と柔軟性を高める。
昨今,事業環境の急激な変化に合わせて,企業のITインフラストラクチャを迅速かつ柔軟に変更可能とすることが求められている。この要求を満たすべく,ITインフラストラクチャのSoftware-defined化が進展している。これは,ITインフラストラクチャを構成するサーバ,ネットワーク,ストレージといったリソースを仮想化し,人手ではなくソフトウェアによりこれらのリソースの配備や構成変更を制御する仕組みである。これにより,企業内ITインフラストラクチャの迅速性や柔軟性を,パブリッククラウドと同等レベルに高めることができる。
日立は,前章で述べたコンテナ向けスケーラブル・データストアのSoftware-defined化を進めた将来像として,日立のデジタルインフラ向け次世代データ基盤の開発を進めている。図2に,日立の次世代データ基盤の概念を示す。図中の左側に,従来のITインフラストラクチャの構成を示す。従来,業務アプリケーションや分散ファイルシステムが必要とするCPU(Central Processing Unit),メモリ,記憶領域といったリソースは,サーバやストレージ装置といったハードウェアにくくりついていた。リソースが追加で必要になった場合,これらのハードウェアのうちのどれがどの程度必要なのかを管理者が判断し,導入や設定を手作業で行わなければならなかった。また,さまざまな種類のハードウェアを個別に調達することにも,手間や時間がかかっていた。
日立の次世代データ基盤では,ハイパーバイザ※6)やコンテナといった仮想化基盤を活用することでリソースを仮想化する。そして,オーケストレータ※7)という運用管理ソフトウェアが,将来必要となるリソースを予測し,必要なリソースを必要な分だけサーバに配備する。これにより,企業内のITインフラストラクチャの迅速性と柔軟性を高めることが可能である。
次世代データ基盤の適用例として,仮想デスクトップインフラストラクチャ(VDI:Virtual Desktop Infrastructure)が考えられる。働き方改革や,感染症対策としてのリモートワーク普及に伴い,VDIへの需要が高まっている。VDIを利用する社員の数は日々変化するが,次世代データ基盤は変化に対して迅速かつ柔軟に対応可能である。
日立の次世代データ基盤では,ストレージの機能は,汎用的なサーバ上で動作するソフトウェアにより提供される。このようなソフトウェアをSDS(Software Defined Storage)と呼ぶ。日立は,以下の特長を持つ独自のSDSであるHES(Hitachi Elastic Storage)を開発している。
- 高い迅速性
HESでは,サーバを増設するだけで,データの読み出し・書き込み性能や格納容量が拡張される。これにより,事業環境の急激な変化に合わせて,必要なリソースを必要な分だけ迅速に増やすことができる。 - 日立独自の高効率データ保護技術
日立の次世代データ基盤は,ハードウェアとしてサーバを使用しているが,あるサーバが閉塞しても,データへのアクセスは継続しなければならない。この要件を満たすために,従来のSDSでは,データを2台のサーバ間で二重化するミラーリングや,3台のサーバ間で三重化するトリプリケーションが用いられるが,オリジナルデータの2倍,3倍の容量を消費してしまう問題がある。この問題を解決するために,複数のオリジナルデータから消失訂正符号を生成し,これらのオリジナルデータと消失訂正符号を複数のサーバに分散格納するErasure Codingと呼ばれる技術も一般的になってきている。これは,ミラーリングやトリプリケーションと同等の耐障害性(データの冗長度)を実現する一方で,ミラーリングやトリプリケーションよりも少ない容量しか消費しないという利点がある。しかし,従来のErasure Codingには,オリジナルデータが複数サーバに分散配置されるため,サーバ間通信が多発し,データの読み出し性能が低下する問題があった。
図3|日立独自のErasure Coding「MEC」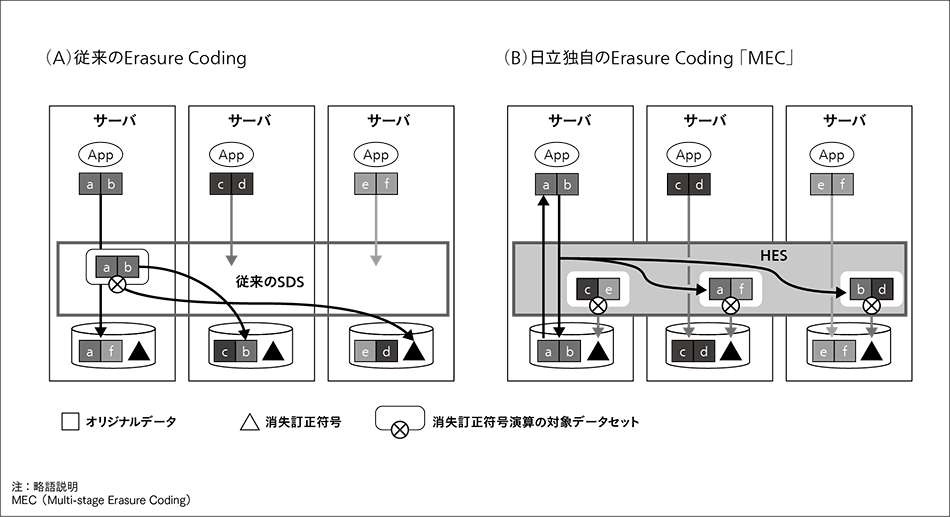 従来のErasure Codingには,データ読み出し時にノード間通信が発生し性能が低下する問題がある。MECは,すべてのオリジナルデータをローカルドライブに記憶する。さらに,自サーバと他サーバのデータから消失訂正符号を生成する。これにより,性能と耐障害性を両立する。
従来のErasure Codingには,データ読み出し時にノード間通信が発生し性能が低下する問題がある。MECは,すべてのオリジナルデータをローカルドライブに記憶する。さらに,自サーバと他サーバのデータから消失訂正符号を生成する。これにより,性能と耐障害性を両立する。
日立は,この問題を解決するべく独自のErasure CodingであるMEC(Multi-stage Erasure Coding)を開発した5)。図3に,従来のErasure CodingとMECの違いを示す。MECは,すべてのオリジナルデータをローカルドライブに記憶し,読み出しを高速化する。さらに,自サーバのデータと他サーバから送られてきたデータを用いて消失訂正符号を生成する。これにより,性能と耐障害性を両立する。
MECに加え,HESは,稼働中に保守作業やドライブ増設などの構成変更を行う機能を備えている。これらにより,HESは,ハードウェアとして汎用サーバを使用しながら,可用性とデータの読み出し性能を高めている。
これらの特長により,日立の次世代データ基盤は,迅速性とともに高可用性,高性能を併せ持ち,日立ならではのSoftware-defined化されたITインフラストラクチャを提供する。
- ※6)
- コンピュータの仮想化技術のひとつである仮想機械(バーチャルマシン)を実現するための制御プログラム。
- ※7)
- 複雑なコンピュータシステムの設定や管理を自動化・自律化するためのソフトウェアやシステム。
4. おわりに
本稿では,LSHを支えるコンテナ向けスケーラブル・データストアを紹介した。また,ITインフラストラクチャのSoftware-defined化の潮流を踏まえ,上記のスケーラブル・データストアを進化させた日立のデジタルインフラ向け次世代データ基盤の開発構想を紹介した。今後,日立の次世代データ基盤は,Lumadaのプラットフォームのソリューションを実現するためのアプリケーションやミドルウェアを最適に稼働させるとともに,これらのアプリケーションやミドルウェアのデータを安全に格納するHyper-converged Infrastructureとして進化し,グローバル市場におけるLumada事業拡大を支える。
参考文献など
- 1)
- Docker
- 2)
- Kubernetes:プロダクショングレードのコンテナ管理基盤 自動化されたコンテナのデプロイ・スケール・管理
- 3)
- Gluster
- 4)
- Github : Heketi
- 5)
- H. Akutsu et al.: MEC: Network optimized multi-stage erasure coding for scalable storage systems, 2017 IEEE 22nd Pacific Rim International Symposium on Dependable Computing, pp. 292-300(2017.1)
- 6)
- Lumada Solution Hub
- 7)
- 日立ストレージソリューション



