
バイオ医薬品開発における創薬プロセス連携プラットフォームの提案
ハイライト
近年,医薬品分野における創薬の主戦場が低分子医薬品からバイオ医薬品にシフトしてきている。特に競争が激化しているADCや多重特異性抗体などの次世代抗体の開発では,従来の抗体に比べて複雑な分子構造を持つことから量産時の品質安定性などの課題が多く,製造難易度が高い。こうした創薬プロセスの下流のCMC・製造領域における課題を,いかに上流の基礎研究段階に組み込んで解決できるかが創薬の成功確率向上とスピード向上に重要である。
本稿では,日立が開発を進めている,創薬プロセス間をシームレスに連携する創薬プラットフォームのアーキテクチャおよび創薬プロセス連携の価値を高めるための,日立独自の数理解析技術を紹介する。
1. はじめに
近年,医薬品分野における創薬の主戦場が低分子薬からバイオ医薬に大きくシフトしている。2000年代初頭は国内承認品目のうち,低分子薬の割合が約80%を占めていたのに対し,2020年代には低分子医薬品が約60%に低下している一方で,バイオ医薬品の割合は年々増加し続けており,世界の売上額上位100位以内の医薬品に限定すると,2019年時点でのバイオ医薬品の割合が約半数を占める1),2)。バイオ医薬品の中でも特に製薬各社の創薬パイプラインの中心となっているのが抗体医薬品であり,限られた有望な標的抗原に対して各社の開発競争が激化している。
こうした中,製薬各社は競争優位性を築くために,従来のモノクロナール抗体から,ADC(Antibody-Drug Conjugate:抗体薬物複合体)や多重特異性抗体などの付加価値の高い次世代抗体の研究開発にシフトしつつある。一方で,次世代抗体は,複数の機能部品を組み合わせた特殊な抗体であり,従来抗体に比べて工業製造の品質が不安定であるという課題がある。そのため,創薬プロセスの下流のCMC(Chemistry, Manufacturing and Control)や製造段階において,量産に向けたさまざまな工夫が必要となる。例えば,現在医薬品として販売されている多重特異性抗体の1種であるIgG(Immunoglobulin G)型バイスペシフィック抗体の事例では,抗体配列の一部を改変することにより抗体の電荷の性質を変化させ,製造の過程で発生する副産物との分離を容易化することで,量産化を実現している3)。
今後,次世代抗体医薬品などのバイオ医薬品の研究開発の競争力を高めるためには,下流側のCMCや製造段階での課題を,上流側の基礎研究フェーズにて検討する,創薬プロセス連携の重要性が高まると考えている(図1参照)。従来は下流で考慮していた製造可能性に関する機能評価を上流の抗体設計時の機能評価に組み込むことにより,手戻りを減らすことができ,創薬プロセス全体の期間短縮・コスト削減につながることが期待される。一方で,個々の創薬プロセスは,部署や業務単位でサイロ化されており,シームレスな連携を前提としていない。各プロセスで発生するデータやモデルのほとんどは,その業務内でのみ利用されることを前提としており,データやモデルのメタデータやインタフェースが業務間で統一されていない。そのため,創薬プロセス連携を実現するためには,その全体でデータやモデルを統制するためのプラットフォームが必要になる。さらに,プラットフォームによってプロセス間でのデータ連携が可能になったとしても,そのデータを扱える解析技術が備わっていないと,データ連携の価値が十分に得られない。例えば,前述したとおり上流で下流の評価指標を取り込むと評価関数が増えるため,多目的最適化技術などの高度化をはじめ,数理解析技術の強化が必要である。
本稿では,こうした創薬プロセス連携の課題解決に向けた,日立の創薬プラットフォームのアーキテクチャを提案する。また,創薬プロセス連携に求められる数理解析技術の事例として,抗体配列設計に多目的最適化手法を取り入れた,日立独自の抗体配列探索技術を紹介する。
図1|創薬プロセス連携の例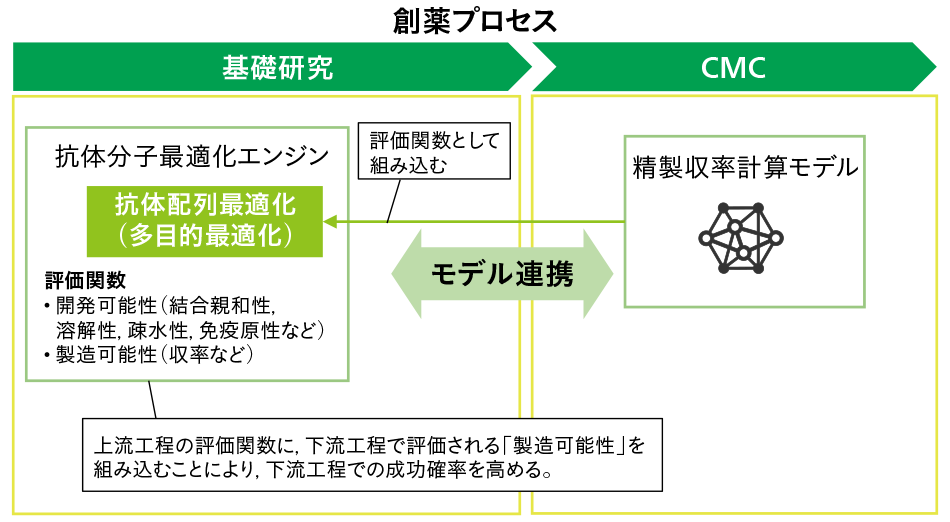 注:略語説明 CMC(Chemistry, Manufacturing and Control)上流工程と下流工程のモデルの相互連携を活用するユースケース例を示す。下流工程で評価される製造可能性に関する評価項目を,上流工程の最適化の評価関数に組み込んでおくことにより,下流工程での成功確率を高める。
注:略語説明 CMC(Chemistry, Manufacturing and Control)上流工程と下流工程のモデルの相互連携を活用するユースケース例を示す。下流工程で評価される製造可能性に関する評価項目を,上流工程の最適化の評価関数に組み込んでおくことにより,下流工程での成功確率を高める。
2. 創薬プラットフォームアーキテクチャ
日立が提案する創薬プラットフォームのアーキテクチャを図2に示す。本プラットフォームの目的は,各プロセスでDMTA(Design-make-test-analyze)サイクルを回しつつ,データ統合を行い,プロセス間でモデルの相互利用を促進することにある。創薬プロセス連携の肝となるのが,創薬プロセス横断で統制の取れたデータ・モデル管理であり,具体的には以下の三つの統制機能が必要と考える。
- 実験計画・実行
研究者や技術者は各自で立案した実験計画(実験プロトコル)に基づいて各種実験を行い,得られた実験データを解析して,その結果に応じて次の実験計画を立案する。このとき,実験計画や実験方法の説明・記述が不十分であると,実験の再現性が低下して得られるデータにばらつきが生じてしまうことがある。例えば,ある実験で得られたデータを,同一もしくは別のプロセスのデータ解析担当者が解析する際に,異なる実験方法で得られたデータが混在すると解析結果の信頼性の低下につながる。このため,実験計画や実験手順の不明確性を排除し,再現性を確保して同じ質の実験データを担保できるような,実験の標準化機能が必要となる。実験をプログラミングのように記述するLab as a Codeコンセプトを採用し,LabOps※1)をベースとした実装により標準化機能の開発を進める。 - オントロジー管理
データを統合するためには,実験だけでなくデータ自体の標準化も必要になる。それぞれのプロセスで得られた生の実験データは,そもそもの実験の目的や実験設備が異なるため,そのままでは統合できない。それぞれの実験データの背景情報(メタデータ)を参照し,各データに合わせて適切な加工を行うことでデータ統合を行うが,制限なしで自由にメタデータを付与できる形にしてしまうと,その内容にばらつきが生じ,適切なデータ加工に多大な工数を要してしまう。そのため,創薬プロセスでのデータ利活用に適した,標準のオントロジー体系でメタデータを設計・管理する必要がある。既にグローバルで標準化活動が進んでおり,R&D(Research and Development)領域におけるOBO Foundry(The Open Biological and Biomedical Ontologies Foundry)やCMC・製造領域におけるNIIMBL(The National Institute for Innovation in Manufacturing Biopharmaceuticals)など,既にグローバルにデファクト化されたオントロジーをベースとして,プロセス連携に必要な要素を追加する形で整備を進める。 - 実験ライフサイクル管理
創薬プロセスにおいてDMTAサイクルを回すには,現場の研究者・技術者に対し,バイオロジー,薬学,生物化学工学などのドメインナレッジに加え,機械学習などのITナレッジが高いレベルで求められる。複数の異分野の専門家が協調しながらプロジェクトを進める必要があるため,プロジェクトのトレーサビリティを高め,相互にナレッジの共有や実施内容の検証が行える環境を整備しなければならない。具体的には,創薬プラットフォーム上の各種実験データや解析モデルに対して,どのような実験プロトコルから得られたデータなのか,どのようにデータ加工したのか,どのようなモデルチューニングを行ったのか,といった詳細を管理し,プロジェクトメンバーが容易に確認できることが求められる。データ処理や機械学習モデルに関してはW3C※2) PROVやW3C ML Schemaなどの標準化活動が進められているため,これらをベースにDMTAサイクルへ拡張することで,実験ライフサイクル全体を管理・追跡する機能を開発する。
以上(1)~(3)に述べたとおり,日立が提案する創薬プラットフォームは,各プロセスにおけるDMTAサイクルを回しつつ,三つの統制機能によりプロセス内/外のシームレスな連携を支援する。
- ※1)
- 研究室の運営を効率化するためのシステムやツールの総称であり,具体的には研究室の機器管理,データ収集,プロセスの自動化,リアルタイムのモニタリングなどの目的で用いられる。
- ※2)
- W3Cは,Massachusetts Institute of Technologyの登録商標である。
図2|創薬プロセス連携プラットフォームのアーキテクチャ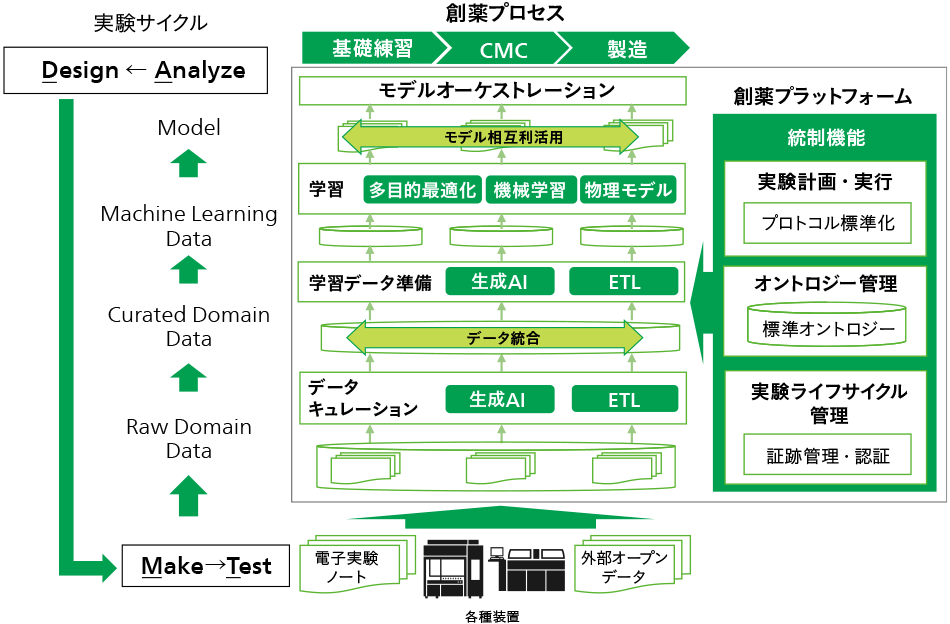 注:略語説明 AI(Artificial Intelligence),ETL(Extract, Transform, Load)各創薬プロセス内でのDMTA(Design-make-test-analyze)サイクルを回しながら,プロセス横断でデータやモデルの相互利活用を可能とする。
注:略語説明 AI(Artificial Intelligence),ETL(Extract, Transform, Load)各創薬プロセス内でのDMTA(Design-make-test-analyze)サイクルを回しながら,プロセス横断でデータやモデルの相互利活用を可能とする。
3. 日立独自の抗体配列探索技術の開発
本章では,プロセス連携のユースケースの一つである抗体配列設計を例に,日立の抗体配列探索技術について紹介する。
現在,抗体の配列設計を計算機上で行うインシリコ創薬の導入が進んでいる。すなわち,配列の生成AI(Artificial Intelligence)モデルを用いて多数の抗体配列を生成し,その配列情報から機械学習や物理モデルを用いて抗体機能を予測する。そして,予測した結果に基づいて配列候補の絞り込みや抗体配列の最適化を行う。このように,ウェット実験の前に計算機上で有望な抗体候補を絞り込むことにより,実験のコストや期間の大幅削減が期待できる。この配列設計において考慮すべき重要なポイントが,「多目的最適化」および「多様な配列候補の生成」である。
抗体開発では,計算機で絞り込んだ初期の抗体候補に対し,結合親和性,溶解性,粘性といったさまざまな抗体機能の評価基準に対し,ウェット実験で評価しながら段階的に絞り込んでいき,最終的にすべての評価基準をクリアできる抗体候補のみが生き残る。このとき,初期の抗体候補として,なるべく多くの評価基準を満たすと予測される配列を選択しておくことが望ましい。すなわち複数の評価関数を持つ多目的最適化問題を解くことが求められる。今後,基礎研究やCMCなど,各プロセスで多様な観点で評価された実験データが蓄積されることにより,高精度な抗体機能予測モデルが拡充されていくと考えられる。そのため,より多くの評価関数に対応した多目的最適化技術への対応が必要になる。
また,すべての物性が計算機上で正確に予測できるわけではないため,抗体候補に対するウェット実験による評価と絞り込みは必ず実施される。この時,もし抗体候補がいずれも似たような抗体配列である場合,一般的に似たような抗体配列は抗体機能も似ているため,あるサンプルが特定のウェット実験で不合格になった場合に,他の抗体候補も含めて全滅してしまうリスクが高まる。そのため,絞り込みの生存確率を高めるために,一定の評価基準をクリアすると同時に,なるべく多様な抗体配列を持つ候補を選択することが望ましい。
日立は,多様性の高い配列を生成可能なGFlowNets4)をベースに,多目的最適化問題に適応するための改良を加えた独自の抗体配列探索技術を開発した5)。本技術を用いて生成した抗体配列候補を,結合親和性,溶解性など五つの評価指標で評価したところ,全抗体候補数のうち全評価指標をクリアした抗体候補数の割合(クリア率)が,従来法の抗体候補のクリア率に比べて10倍高いという結果が得られた。現在,本技術の実用化に向けて,学習効率の向上や,より優れた解を探索できる探索アルゴリズムの改良に取り組んでいる。
4. おわりに
本稿では,今後のバイオ医薬品開発の競争力強化に向けた日立の取り組みとして,創薬プロセス連携のための創薬プラットフォーム構想と,日立独自の抗体配列探索技術について紹介した。現在,製薬企業やパートナー企業との協創活動を通じて本プラットフォームの製品開発を推進しており,Hitachi Digital Solution for Pharma6)のソリューション群の一つとして近日中に提供を開始する計画である。
参考文献など
- 1)
- 経済産業省,バイオCMO/CDMOの強化について(2020.11)
- 2)
- 医薬産業政策研究所,新薬における創薬モダリティのトレンド
- 3)
- Z. Sampei et al., Identification and Multidimensional Optimization of an Asymmetric Bispecific IgG Antibody Mimicking the Function of Factor VIII Cofactor Activity,PLOS ONE(2013.2)
- 4)
- M. Jain et al., Biological Sequence Design with GFlowNets,Proceedings of Machine Learning Research(2022)
- 5)
- 豊村 崇,外:抗体配列生成への複数モードサンプリング生成モデルの適用と配列多様性向上の検討,FIT2023(第22回情報科学技術フォーラム)(2023.9)
- 6)
- 日立製作所,Hitachi Digital Solution for Pharma



